..Hammer как продукт имеет две особенности. И,
если аппаратное решение по большей части
логично и предсказуемо, в программной AMD
приготовила изрядный сюрприз. Hammer
поддерживает новое расширение архитектуры
х86 – х86-64. Как нетрудно догадаться по
названию, это расширение адресного
пространства и операндов, сравнимое с
переходом с 286-го на 386-ой. Когда-то такую
операцию индустрия под чутким руководством
Intel достаточно безболезненно проделала (в
основном по причине большей
производительности даже в «старых» кодах)
– посмотрим, как это получится у AMD. Но
позвольте, – скажет начитанный читатель, –
на рынке уже есть 64-битная архитектура от
Intel. Как же называть Itanium? Есть-то она есть, да
только вот х86 там и не пахнет – режим
совместимости с х86, хотя и присутствует
формально, имеет крайне низкую скорость. Но
самое неприятное не в этом – с низкой
скоростью можно было бы примириться.
Совместное исполнение х86 кодов и 64-разрядных
команд Itanium приводит к падению
производительности на порядки. Если
немного утрировать – один единственный 32-битовый
драйвер мыши способен превратить
скоростной процессор в дорогостоящий
тормоз. Причина, в общем-то, понятна – Intel
всеми силами пытается забыть х86 на рынке
высокопроизводительных вычислений. Вот
только вопрос – согласится ли на это
остальная индустрия…
С этой точки зрения решение AMD гораздо
менее революционно – просто введено еще
одно расширение хоть и не лучшей, но, без
сомнений, самой распространенной
архитектуры. Собственно, это решение
назрело давно – у многих пользователей
потребности давно переросли куцые
ограничения х86. Кроме того, решение от AMD
позволяет обойтись без дорогостоящего
перехода на новую систему команд –
необходимо сделать лишь минимальные правки,
чтобы воспользоваться преимуществами
расширенного адресного пространства. А 32-разрядные
программы вообще не нуждаются ни в какой
адаптации и работают абсолютно прозрачно.
Для них Hammer – обычный процессор х86.
К этой бочке меда, однако, надо добавить
ложку реальной ситуации. А она такова, что к
сожалению, наборы IA64 от Intel и x86-64 от AMD
несовместимы друг с другом. Посему только
рынок рассудит, кто же из них выживет. С этой
точки зрения, для AMD крайне важно, чтобы
процессор получился бы быстрым как в 32-, так
и в 64-битовом режиме. Это необходимо для
того, чтобы даже при провале х86-64 (а мощь
маркетинговой машины Intel мы с вами знаем)
скоростные характеристики Hammer сделали AMD
лидером по скорости на рынке х86-32. Только
тогда AMD может рассчитывать на хорошие
продажи своего продукта. Хотя, думается, в
реальности все три архитектуры будут
сосуществовать – подавляющее большинство
пользователей, включая вашего покорного
слугу, абсолютно не нуждается в ближайшем
будущем в 64-х битах ни под каким соусом. Те
пользователи, которые в силу финансовых,
исторических, или иных причин привязаны к х86,
но нуждаются в максимальной скорости –
будут использовать х86-64. Те же пользователи,
которые планируют свои задачи с нуля –
будут присматриваться к Itanium.
Однако, со скоростными качествами Hammer все
более или менее понятно – Pentium 4, если и
сможет с ним конкурировать, то только за
счет намного более высокой частоты. Гораздо
интересней ситуация c многопроцессорными
системами – архитектура Hammer смотрится в
таких системах намного предпочтительней
современных решений от Intel. Тому есть
несколько причин:
- первая (и, пожалуй, самая важная) –
разные подходы, используемые AMD и Intel. Суть
их в том, что, как и текущее решение на Athlon,
AMD использует в многопроцессорных
системах на Hammer соединение точка-точка. В
отличие от этого, Intel остается
приверженцем общей шины.
- и вторая, вытекающая из первой причины –
совершенно новая (для х86) архитектура
многопроцессорных систем.
Однако об этом мы поговорим позднее, а
пока глянем – что же внутри Hammer. Что мы
видим? И контроллер DDR памяти, и контроллер
HyperTransport... А что же скрывается под
таинственным названием Hammer core? Как мы видим,
в основном ядро похоже на ядро Athlon XP, но
многие буферы и емкость планировщика
увеличены. Слегка увеличена и длина
конвейера – двенадцать стадий у Hammer взамен
десяти у Athlon, причем удлинили стадию
декодирования (превращения х86 инструкций в
микрокоманды). Что ж, это должно помочь
наращивать частоту. Однако, чтобы снизить
негативные последствия неправильного
предсказания переходов, которые из-за более
длинного конвейера Hammer опаснее таковых для
Athlon – необходимо увеличить точность
предсказаний. Что же планирует сделать AMD
для снижения негативных последствий
неправильных переходов? Собственно, это
очевидно – надо снизить количество таких
переходов. Для этого и предназначены
увеличивающиеся кэши всех уровней,
увеличенные буферы и более длинная история
переходов.
Какие прелести ждут нас от переноса
контроллера памяти в ядро? Поддерживается
как 64-битовая, так и 128-битовая архитектура
памяти и память РС2700. То, что поддерживается
ECC – просто необходимость для систем такого
уровня, поэтому преимуществом это не
считаем.
Теперь самое интересное – построение
многопроцессорных систем на Hammer.
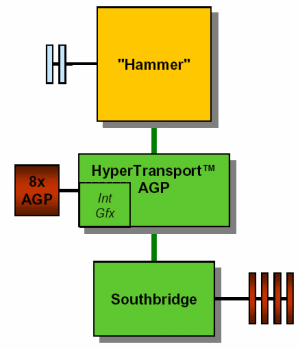
Однопроцессорные системы
Особо комментировать здесь нечего –
взглянем на рисунок. К процессору
присоединена память (скорее всего 64-бит
каналом для уменьшения стоимости). К
процессору же присоединены PCI шина (один
HyperTransport контроллер) и AGP 8х (второй HyperTransport
контроллер). К первому присоединен еще «южный
мост» чипсета, в котором, по видимому, и
находятся всякие USB, Monitoring и прочее.
Возможно, при необходимости в максимальной
производительности память сделают 128-бит, а
PCI – 64/66.
Двухпроцессорные системы
Здесь начинается более интересная
ситуация – системы на AMD и Intel сильно
отличаются по идеологии. Для Intel характерна
общая шина для 2-х процессоров и памяти. Это
приводит к двум следствиям:
- Монтаж двухпроцессорной платы для
систем от Intel проще и дешевле.
Соответственно, у AMD – сложней и дороже.
- Поскольку шину делят 2 процессора и
память, процессоры в такой системе
практически всегда недогружены. Слегка
исправляют ситуацию большие кэши, которые
Intel интегрирует в процессоры. Однако
кардинально исправить ситуацию они не в
силах – такова, увы, идеология построения
двухпроцессорных систем от Intel. Отсюда же
понятно, почему не имеет смысла
использовать память с пропускной
способностью, большей, чем шина – она
просто не будет использована (разве что
теоретически есть возможность другим
устройствам, минуя процессор, обратиться к
памяти, пока процессор читает или пишет
данные. Практически прирост не превышает
нескольких процентов.)
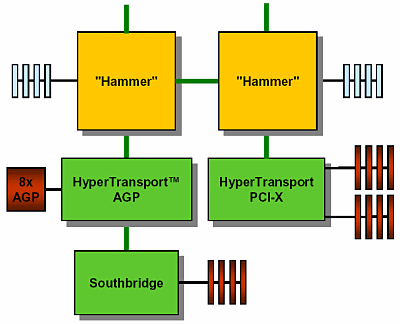
Теперь посмотрим на систему конкурента –
к каждому процессору подведена своя память.
Причем 128-битным каналом. К одному из
процессоров подключены PCI64/66, AGP; ко второму
– PCI64/66.
Интересно – ранее аналогичной системы на
х86 рынке не было… Собственно, из такой
технологии подключения вытекает несколько
следствий:
- Когда процессор обращается к своей
локальной памяти – все понятно. Когда к
чужой – он по HyperTransport запрашивает данные у
контроллера памяти второго процессора.
Поскольку тому необходимо попутно
обслуживать свой собственный процессор –
этот самый контроллер должен быть
достаточно умным, дабы уметь обслуживать
несколько процессоров.
- Для достижения максимальной
производительности имеет смысл следить за
«локальностью» данных той или иной задачи,
то есть по возможности следует размещать
данные и команды того или иного процесса в
памяти того процессора, который его
обслуживает. Имеет смысл научить
операционную систему сортировать процессы
таким образом, чтобы выполнялось это
правило. В случае, если данные в локальной
памяти не помещаются, придется обратиться к
соседнему процессору (его памяти), что
замедлит работу. Правда, AMD обещает, что
замедление от подобной неприятности будет
скомпенсировано уменьшившейся
латентностью контроллера памяти (по
сравнению с текущими контроллерами в
чипсетах).
- При обращении к PCI и AGP, находящихся у
соседнего процессора, ситуация не
ухудшается, поскольку дополнительные
задержки из-за обращения к не локальной
памяти намного меньше времени отклика
устройств на PCI и AGP шинах.
- Самой нагруженной магистралью будет
межпроцессорная шина HyperTransport. Именно ее
имеет смысл делать самой быстрой. В идеале
она должна позволить читать процессорам
данные из памяти друг друга, плюс периферия
должна иметь возможность делать тоже самое.
Таким образом, получаем, что эта шина должна
пропускать удвоенный трафик памяти плюс
трафик AGP и PCI. Однако… Для этого надо почти
14.4 ГБ/сек (в случае 128-битной памяти РС2700).
Таким образом, цифра 6.4 ГБ/сек у старшего
варианта HyperTransport уже не кажется слишком
большой… Правда, пока не задействован
третий контроллер, ему имеет смысл быть
подключенным так же, как и второму – как
шина между процессорами. Тогда вместе они
обеспечат 12.8 ГБ/сек, что уже гораздо лучше.
Впрочем, будет ли реализован такой вариант
– непонятно…
- Естественно, создание плат под эту
систему – гораздо более сложное и дорогое
занятие. Поэтому на первом этапе такие
системы наверняка будут относительно
дороги. Бонусом, однако, практически
наверняка станет непревзойденная
производительность.
- Начиная с двухпроцессорных систем
появляется такой сектор оборудования, как
сервера, а для этого сектора одним из самых
важных параметров является надежность. Что
предлагает нам архитектура Hammer в этой связи?
В общем случае, архитектура точка-точка (реализованная
уже в сегодняшних Athlon) позволяет «отключать»
на ходу процессоры или, скажем, память. То
есть, при выходе процессора или модуля из
строя есть возможность продолжать работу.
При восстановлении работоспособности или
замене оборудования работу можно
продолжить. Для этого необходима поддержка
со стороны материнской платы (она должна
отключить питание на устройствах) и
операционной системы, которая должна
отключить процессор/не использовать адреса
памяти…
Кардинальное отличие такой системы от
общей шины в архитектуре Intel – в случае
выхода из строя одного из процессоров
нормальная работа в шинной архитектуре
невозможна. Собственно, наверняка Hammer будет
поддерживать еще более развитые варианты
подобного сервиса, например, добавлять
процессоры при нехватке вычислительной
мощности, или на «горячую» менять их на
более мощные, не выключая и не останавливая
системы… Добавим сюда Hot Plug PCI, и мы получим
почти идеальный (с точки зрения надежности)
вариант. Осталось разве что придумать, как
на ходу поменять материнскую плату…
Ну что ж, некоторые последствия мы описали.
Собственно, в определенной степени это
развитие идей сегодняшних
двухпроцессорных систем на Athlon –
большинство идей логичны и расширяют «узкие»
места современных архитектур.
Четырехпроцессорные системы
Ну что же, взглянем на 4-х процессорную
систему. Вот процессоры, каждый из которых
снабжен локальной памятью со 128-битовой
шиной. Вот по 2 шины HyperTransport – процессоры
расположены квадратом, каждый присоединен
к двум соседям.
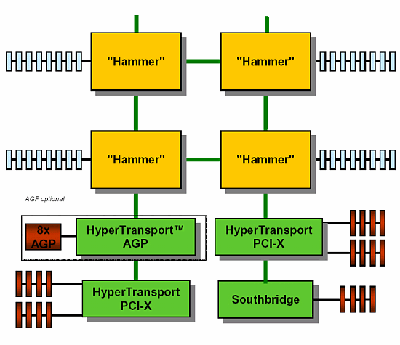
Собственно, ряд следствий можно
продолжить из предыдущей части. Итак:
1. Межпроцессорные шины нагружены еще
сильнее, чем в предыдущем примере. Это
приведет к дефициту пропускной способности,
и снижению масштабируемости. То есть,
производительность системы подрастет
меньше, чем могла бы, например, в случае
присоединения каждого процессора к
центральному межпроцессорному
маршрутизатору (по аналогии с решениями от
Sun – правда, цена такого решения явно больше).
Однако производительность системы из 4-х
Hammer по отношению к двухпроцессорной на тех
же Hammer вырастет намного больше (в среднем),
чем в случае системы на процессорах Intel. Это
очевидно.
2. Интересная ситуация возникает с памятью,
поскольку каждый процессор владеет только
четвертью общей памяти, в большинстве
случаев необходимые ему данные будут
находиться у других процессоров. Не совсем
понятно, как AMD собирается реализовать
эффективную пересылку данных.
3. С ростом скорости процессоров и,
особенно, скорости HyperTransport, задержки,
связанные с пересылкой данных из «чужой»
памяти, будут уменьшаться. И, наоборот,
задержки при большой нагрузке будут расти,
но медленнее, чем у стандартных шинных
систем сравнимой производительности (около
6.4 ГБ/сек, по данным AMD).
Кстати, достаточно интересен вот какой
вопрос – может ли 4-х процессорная ситема на
базе Hammer изображать из себя два компьютера?
Согласитесь, было бы достаточно красиво,
ведь далеко не все приложения могут
пользоваться 4-мя процессорами. А в этом
случае у нас было бы два компьютера в одном
флаконе, на каждом при этом могла бы
исполняться своя операционная система со
своими задачами… Кстати, это соотношение
может быть и три к одному, например,
запустили мы сложную и ресурсоемкую
расчетную задачу на трех процессорах,
предварительно выделив 4-ый процессор как
отдельный.
Вот уж действительно история развивается
по спирали – сначала были большие машины,
потом стали распространенными персоналки,
а теперь мы фактически идем опять к большим
машинам. Только уже на столе :-).
Можно еще помечтать, ведь у нас можно из 4-х
процессорной системы сотворить две
двухпроцессорных, сделать их серверами,
повесить на них разные задачи, и разрешить
обмениваться данными не по сети, а по
HyperTransport, что гораздо быстрее… Да много
можно придумать применений такому подарку
судьбы, как архитектура Hammer – лишь бы AMD
справилась. И с финансовой, и с технической
стороной.
8-процессорная система
Ухх! Если эта штука станет
действительностью – обладателям многих
серьезных RISC серверов и станций придется
стереть снисходительные ухмылки и
судорожно пересчитывать деньги :-). Потому
как придется туго – х86 уже не мелкая сошка с
«несчастными» 4 ГБ адресуемого
пространства. Эта архитектура подросла,
окрепла в боях в «гражданской войне» между
Intel и AMD, и готова продемонстрировать
окрепшие мышцы и зубы. Теперь понятно, для
чего пришлось вводить х86-64 – действительно,
городить такое на х86-32 просто незачем.
Необходима такая система команд, которая
действительно почувствует прирост от
возможности использования (как скромно
пишет AMD) до 64-х модулей памяти общим объемом
до 128 ГБ.
Восемь процессоров… Чем их можно
нагрузить? :-) Посмотрим на рисунок:
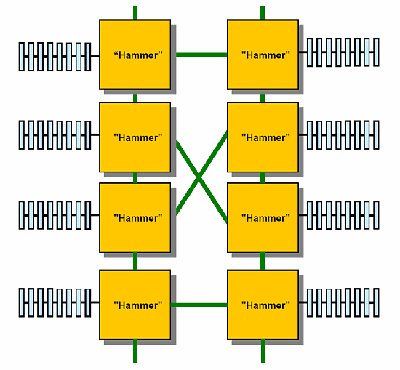
Отличие от предыдущих систем –
центральные процессоры не имеют
периферийных шин, потому что все три
HyperTransport шины заняты межпроцессорными
связями.
Кстати, еще раз обратим внимание на
неодинаковость центральных и периферийных
процессоров. До этого момента мы неявно
полагали, что все процессоры у нас
одинаковы. Но почему? Вроде этого в явном
виде никто не требовал. На периферию
системы (для работы с памятью и периферией)
есть смысл поставить более быстрые
процессоры. А вот в центр - можно и
помедленнее. Гм… Интересно.
N-процессорные системы
Действительно, к чему мелочиться?
Попробуем представить себе систему из
большого количества процессоров. Так…
Вариантов два:
1. Интегрировать в процессор еще одну (или
больше) шину HyperTransport и создать трехмерную
структуру (вернее, слоистую – процессоры
будут расположены плоскостями друг над
другом). Конечно, под эту конструкцию еще
операционную систему соответствующего
уровня написать надо.
2. Можно также не переделывать процессоры,
а создать дополнительную логику обвязки,
аналог GigaPlane от Sun. То есть коммутатор с
огромной пропускной способностью
внутренней шины (что намного легче сделать)
соединяет несколько, например, 8
процессоров. При этом каждая шина HyperTransport
от каждого процессора несет на себе только
нагрузку от родного процессора, и ничего
лишнего. А от одного процессора к другому
передает коммутатор – так оно получше с
масштабируемостью будет. Теперь еще
припомним, что у каждого процессора три
шины HyperTransport, и его, соответственно, можно
присоединить к трем коммутаторам. Делая эти
подключения частично перекрывающимися,
можно добиться того, что путь данных в
системе будет, во-первых, очень быстрым, а во-вторых
– не единственным. Что кардинально меняет
представление о надежности системы –
теперь незаменимых узлов попросту нет. К
тому же, это сильно снижает (а для
небольшого количества процессоров –
полностью убирает) проблему нехватки
скорости внутренних межпроцессорных шин
HyperTransport.
Так, стоп – пора возвращаться на землю. А
то мы уже почти построили суперкомпьютер. :-)
Буквально замок на песке, хотя каждый наш
шаг был логичным и предсказуемым. Если при
разработке этой архитектуры инженеры AMD все
это предвидели (а сомневаться причин вроде
нет) – нам остается только снять шляпу. На
сегодняшний день это, пожалуй, самое
масштабируемое решение в истории
компьютеров (среди известных нам).
Комментарий автора:
Не хотелось бы, чтобы автора отнесли к
фанатам AMD – напротив, автор консервативен,
уныл, и практически не поддается уговорам
купить что-то новое. :-) Тем более он не
склонен к фанатизму в каком бы то ни было
виде. Просто хотелось бы отойти от
тривиального спора «кто сильнее - слон или
кит» и оглянуться – а что изменилось на
компьютерном горизонте?
|

